
YOLOv5: Fast and Accurate Object Detection

Unleashing the power of code in its natural habitat 🚀 | Software Engineer & Architect 💻 | ML Enthusiast 🤖 | Game Design Maverick 🎮 | Crafting the future one line of code at a time! 🔮✨
Introduction: The Crucial Role of Object Detection
In the realm of computer vision, object detection takes center stage, with the primary goal of identifying objects within images or video streams. This task is pivotal in a wide range of applications, from security systems to autonomous vehicles. Let's have a leap through the categories.
Categories
Object detection methods can be broadly classified into two categories: non-neural and neural approaches.
Non-Neural Methods
Viola-Jones: This approach harnesses Haar features to achieve robust and efficient object detection.
SIFT (Scale-Invariant Feature Transform): SIFT extracts key points and descriptors from images, enabling effective object recognition.
HOG (Histogram of Oriented Gradients): HOG is a feature descriptor that characterizes objects based on their shape and appearance.
Neural Network Methods
R-CNN Family (Region-Based Convolutional Neural Networks): These models leverage region proposals to enhance object detection accuracy.
SSD (Single Shot Detector): SSD is renowned for real-time object detection, accomplishing this task in a single pass through the network.
Retina-Net: Exceptional at managing objects of varying scales and aspect ratios.
YOLO (You Only Look Once): YOLO is a real-time object detection marvel that performs the detection and classification of objects in a single, efficient pass through a neural network.
Understanding YOLO
What is YOLO?
You Only Look Once (YOLO), born in 2016, stands as a formidable object detection algorithm renowned for its speed and accuracy.
In a single efficient pass through the network, YOLO predicts both bounding boxes and object classes, rendering it perfect for real-time applications. YOLO's elegance and its proficiency in handling diverse objects have propelled it to popularity.
Training Your YOLO Model
When it comes to training your YOLO model, you have the freedom to harness datasets such as those provided by Roboflow.
By creating an account and downloading YOLO-compatible formats, you are poised to embark on the journey of customizing your YOLO model to suit your specific objectives.
To acquire your custom dataset, execute the following command:
curl -L "https://public.roboflow.ai/ds/YOUR-LINK-HERE" > roboflow.zip; unzip roboflow.zip; rm roboflow.zip
Before you begin training your YOLOv5 model, you need to set up data.yaml configuration file. This file is essential for defining key parameters, including:
The location of your YOLOv5 image folder.
The path to your YOLOv5 labels folder.
Custom class information.
This data.yaml file serves as a blueprint for your training process. It provides the necessary instructions for your YOLOv5 model, ensuring it understands your dataset, class labels, and how to handle them effectively during training.
Installing the YOLOv5 Environment
To start with YOLOv5 we first clone the YOLOv5 repository and install dependencies. This will set up our programming environment to be ready to run object detection training and inference commands.
!git clone https://github.com/ultralytics/yolov5.git
%cd /content/yolov5
!pip install -U -r yolov5/requirements.txt
YOLOv5 Model Configuration and Architecture
For our YOLOv5 model, we've opted for the leanest and swiftest base model available. However, it's important to note that you have a range of YOLOv5 model options to choose from, depending on your specific requirements:
YOLOv5s
YOLOv5m
YOLOv5l
YOLOv5x
Training Your Custom YOLOv5 Detector
Now that we have our data.yaml and yolov5s.yaml files primed and ready, we're all set to commence our training journey.
To initiate the training process, execute the training command with the following pivotal options:
img: Specifies the input image size.batch: Determines the batch size for training.epochs: Sets the number of training epochs.data: Points to the path of ourdata.yamlconfiguration file.cfg: Specifies the model configuration (in this case,yolov5s.yaml).weights: Allows you to specify a custom path to pre-trained weights.name: Defines the name for your training results.nosave: Saves only the final checkpoint, minimizing disk space usage.cache: Enables image caching to expedite the training process.
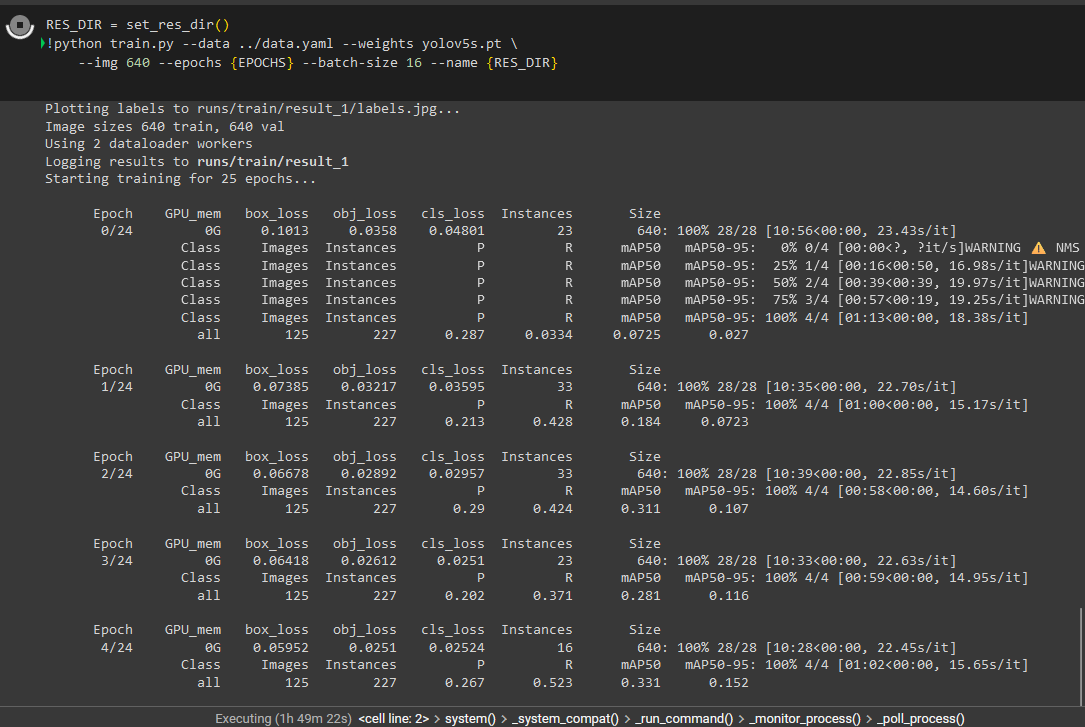
Execute this training command to kickstart your YOLOv5 model customization and training.
!python train.py --data ../data.yaml --weights yolov5s.pt \
--img 640 --epochs {EPOCHS} --batch-size 16 --name {RES_DIR}
After training it will save in this path as best.pt
runs/train/results_1/weights/best.pt
Run YOLOv5 Inference on Test Images
Once our YOLOv5 model has been meticulously trained, it's time to put it to the test by making inferences on test images. After the training process has concluded, the model weights will be securely stored in the 'weights/' directory.
You can employ the 'source' parameter to specify the source of inference. It's versatile and can accept a variety of inputs, including:
A directory containing multiple images
Individual image files
Video files
Even a webcam's input port
To put our model to the test with test images, utilize the following command:
!python detect.py --weights runs/train/{RES_DIR}/weights/best.pt \
--source {data_path} --name {INFER_DIR}
Here are some visualizations after running test images.

Image Courtesy: Roboflow

Image Courtesy: Roboflow
To further assess the performance of our trained model, we've acquired random images from the internet. These additional tests serve to showcase the model's versatility and effectiveness, Here are the results of these evaluations

Image Courtesy: click4vector

Image Courtesy: pexels
Conclusion
Training your custom YOLO object detection model is a rewarding experience. YOLO stands out for its lightweight and user-friendly nature, enabling quick training, fast inferences, and outstanding performance. Whether you're working on real-time applications or complex projects, YOLO is a versatile and powerful tool in your computer vision toolkit.
Happy Coding…. 🙏🙏🤝



